1.はじめに
今回は、OCR機能を使用しPDFから文字列を抽出する方法を記載します。事前準備としてTesseractのインストールが必要になります。未だインストールしていない方は、Power Automate DeskTop OCRでPDFの文字列を抽出①を参照しTesseractのインストールをお願いします。
2.フローを作成
所定のフォルダ(今回はC:\PDF)に配置したPDFファイルをEdgeで開きPDFファイルから文字列を抽出するフローを作成します。
2-1.PDFファイルをEdgeで開く設定
C:\PDFに配置した「都道府県別面積の順位.pdf」を右クリック→「プログラムから開く」をクリック→「別のプログラムを選択」をクリックします。
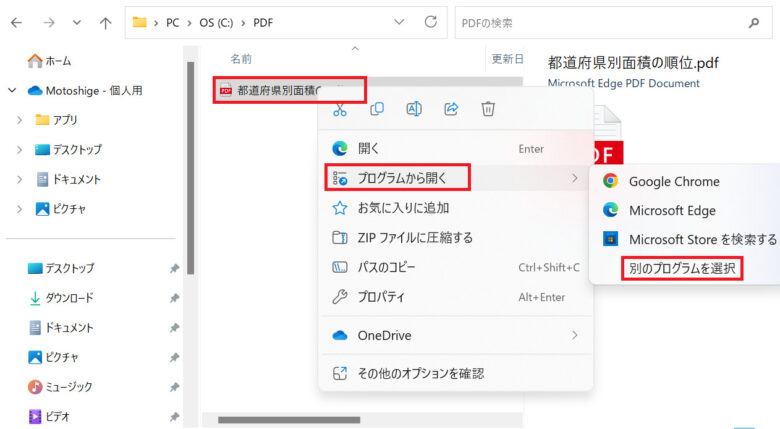
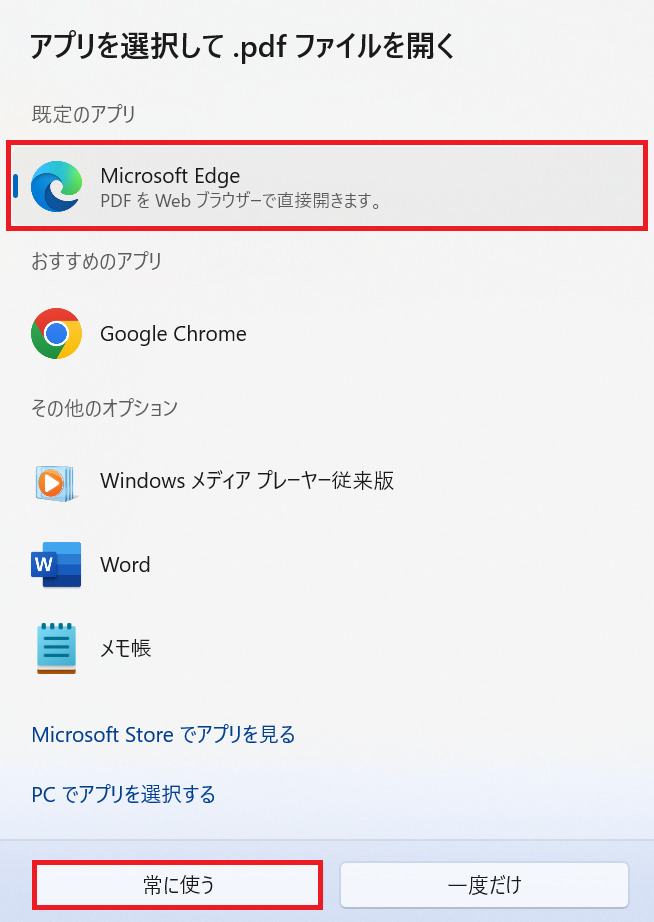
「Microsoft Edge」を選択し、「常に使う」をクリックします。
これで、PDFファイルをEdgeで開く設定は終了です。
2-2.PDFファイルをEdgeで開く
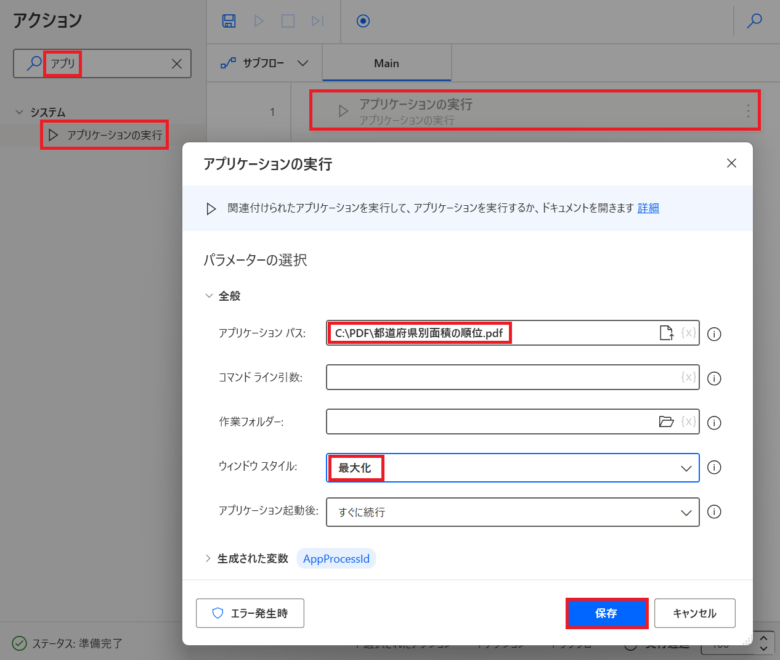
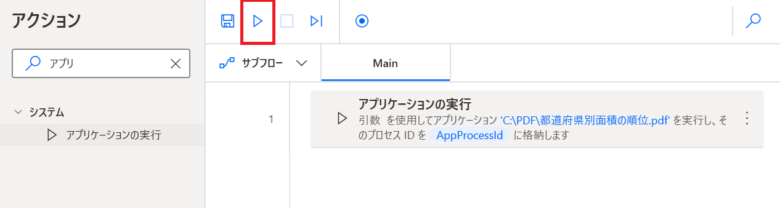
「アクションの検索」に「アプリ」を入力し「アプリケーションの実行」をMainペインにドラッグ&ドロップします。「アプリケーションパス:」に「C:\PDF\都道府県別面積の順位.pdf」を入力し、「ウィンドウ スタイル」に「最大化」を入力し「保存」をクリックします。
「▷」(実行)をクリックしPDFファイルをEdgeで開くことを確認します。
2-3.PDFファイルの表示の固定化
OCRは座標指定するためPDFファイルを開くごとに位置や表示サイズが変わると正しく文字列を抽出できなくなる可能性があります。そのため、PDFファイルの表示の固定化を行います。
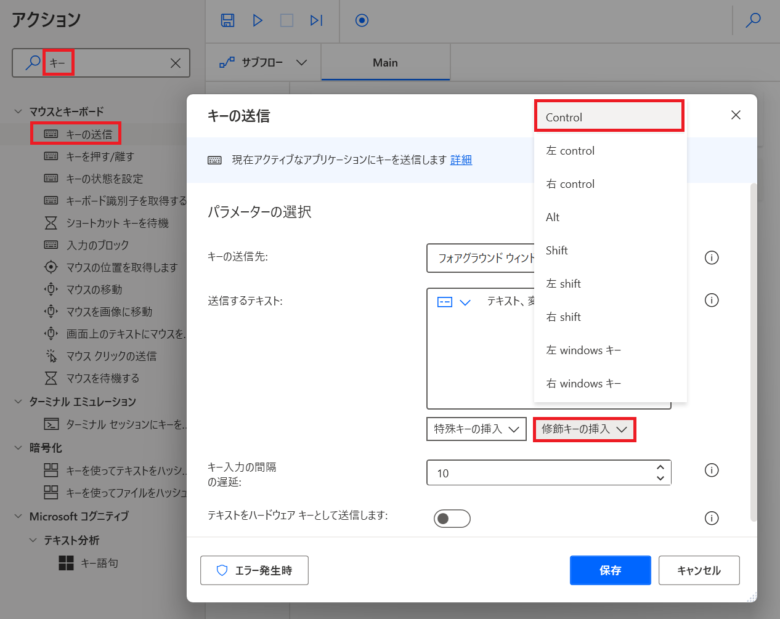
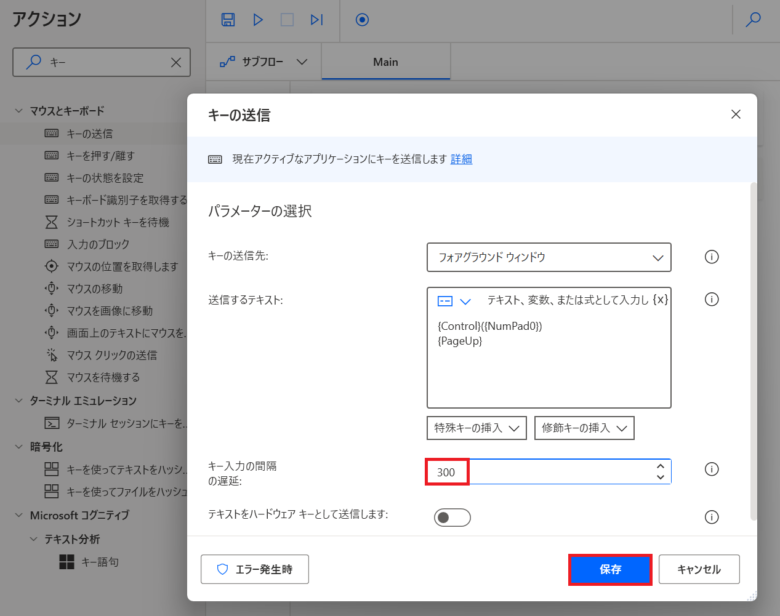
「アクションの検索」に「キー」を入力し、「キーの送信」をMainペインにドラッグ&ドロップします。「修飾キーの挿入」をクリックし、「Control」をクリックします。
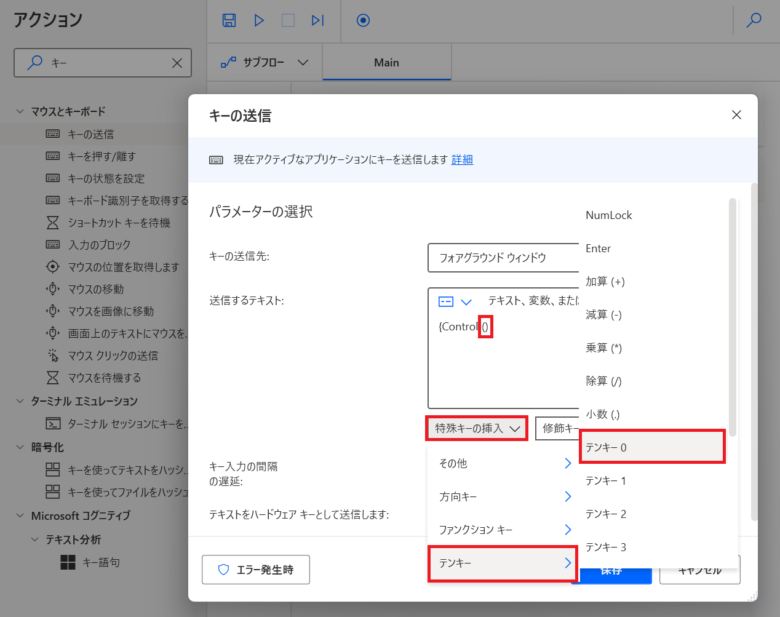
{Control}()の「()」の中にカーソルを合わせて「特殊キーの挿入」をクリックし、「テンキー」をクリックし、「テンキー0」をクリックします。
「{Control}({NumPad0})」の最後にカーソルを合わせ改行します。「特殊キーの挿入」をクリックし、「その他」をクリックし、「Page up」をクリックします。
特殊キーと修飾キーについては、Edgeのキーボードショートカットを参照ください。
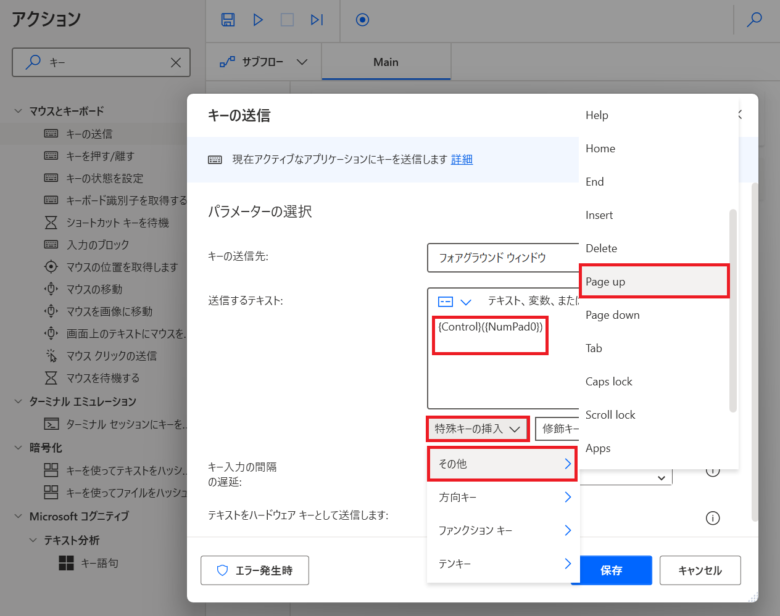
「キー入力の間隔の遅延:」のデフォルト値は「10」ミリ秒です。これは、「Ctrl+0」が実行されてから「Page up」を実行する間隔です。「10」ミリ秒では、短く正常に動作しないことがあるため、「300」ミリ秒に変更し、「保存」をクリックします。これでも正常に動作しない場合は、更に実行間隔を空けてください。
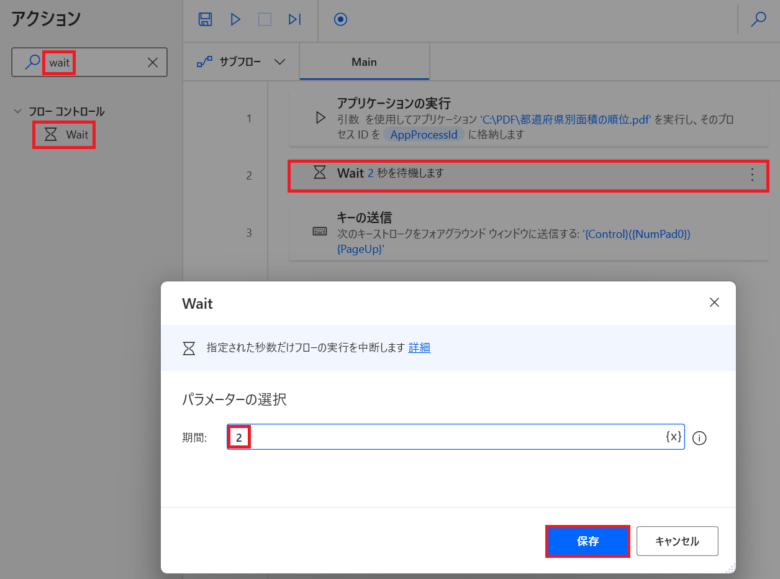
「アプリケーションの実行」と「キーの送信」の間隔が短いため正しく動作しない可能性があります。そのため、「アプリケーションの実行」と「キーの送信」の間にWaitを挿入します。
「アクションの検索」に「wait」を入力し、「Wait」をMainペインにドラッグ&ドロップし、「期間:」に「2」秒を入力し、「保存」をクリックします。
管理人の環境では、「1」秒ではPDFファイルが開かなかったので「2」秒を設定しました。
2-4.OCRの設定
PDFファイルから抽出する文字列の座標取得をレコーダーにお願いし、人が指定した箇所を座標に自動変換してくれます。レコーダーは、一つの抽出する文字列に対して、抽出する文字列とアンカー(ずれに対して読み取り精度を向上させるため)の2つの設定が必要になります。今回は、抽出文字列を「面積(k㎡)」、アンカーを「順位」とします。この設定を行う前に、PDFファイルを開いておく必要があるため「▷」をクリックしフローを実行します。PDFファイルをEdgeで開いたままにします。
「レコーダー」をクリックします。
「3点リーダー」をクリックし「画像記録」をクリックします。
「画像記録」の背景が青色になっていれば設定が反映されています。
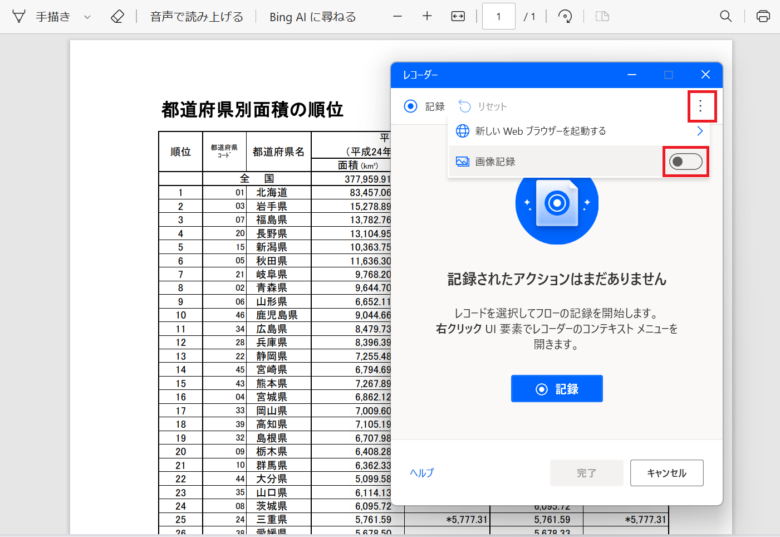
「記録」をクリックし記録を開始します。
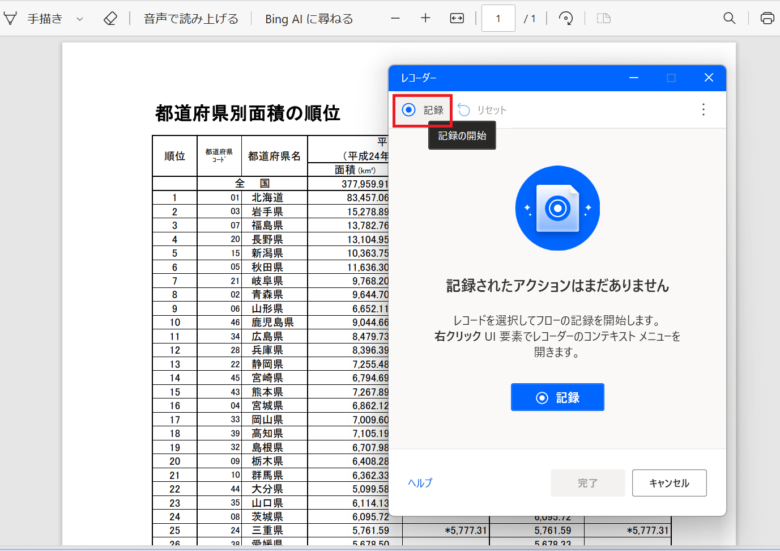
画面を右クリックし、「画像からテキストを抽出する」をクリックします。

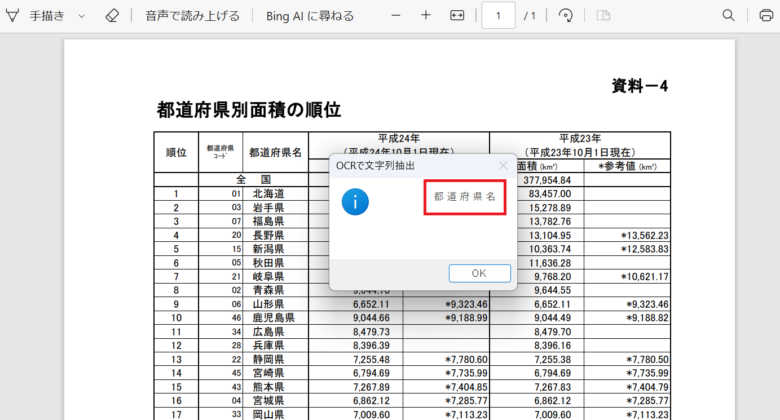
最初に「都道府県名」をドラッグし範囲指定します。これで抽出文字の座標を取得しました。次に「順位」をドラッグし範囲指定します。これでアンカー座標を取得しました。2つの設定を行ってから「完了」をクリックします。
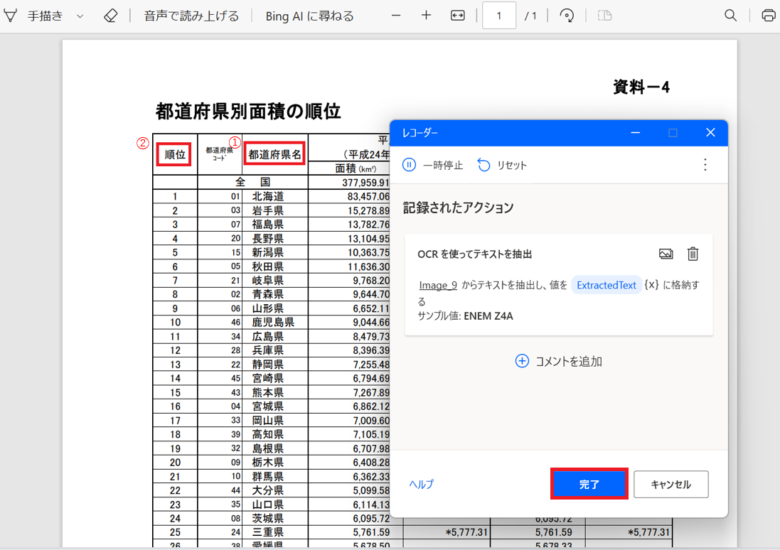
不要な2つの「コメントアクション」が作成されていますので順番に「コメントアクション」を右クリックし「削除」をクリックします。
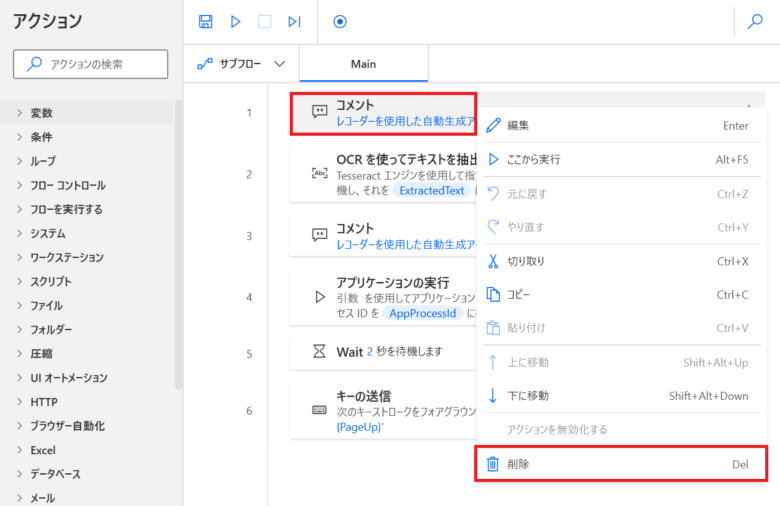
「OCRを使ってテキストを抽出」アクションが一番上になっていまう
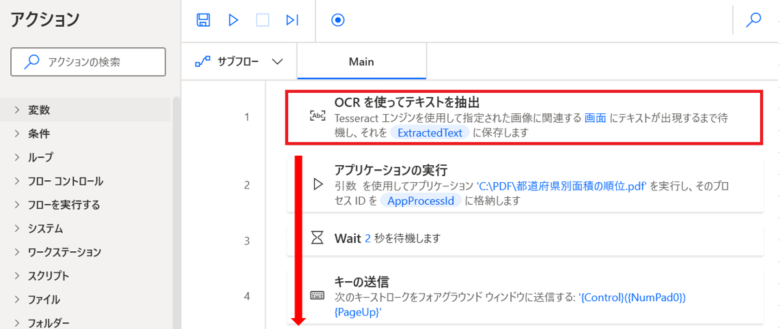
「OCRを使ってテキストを抽出」アクションをダブルクリックします。
下記設定変更を行います。
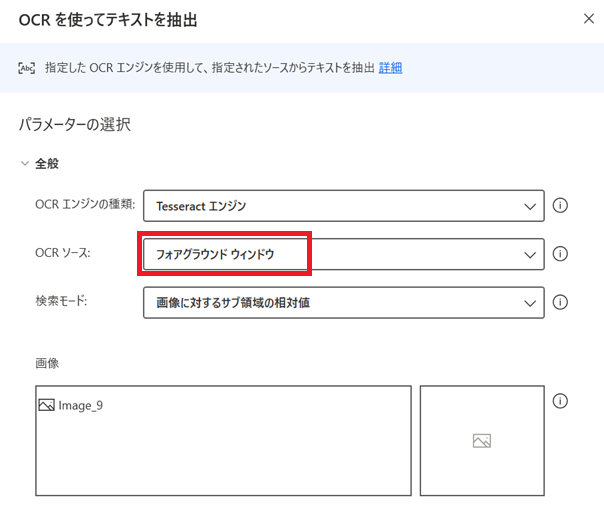
・「OCRソース:」に「フォアグラウンド ウィンドウ」を選択します。
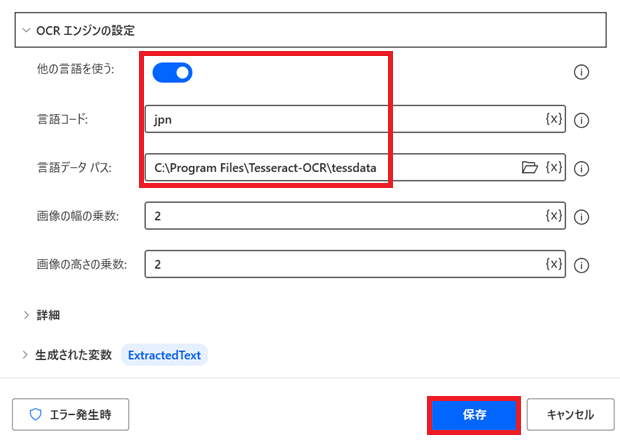
OCR エンジンの設定
・「他の言語を使う:」を「ON」にします。
・「言語コード:」に「jpn」を入力します。
・「言語データ パス:」に「C:\Program Files\Tesseract-OCR\tessdata」を入力します。
上記設定変更後に「保存」をクリックします。
2-5.実行結果
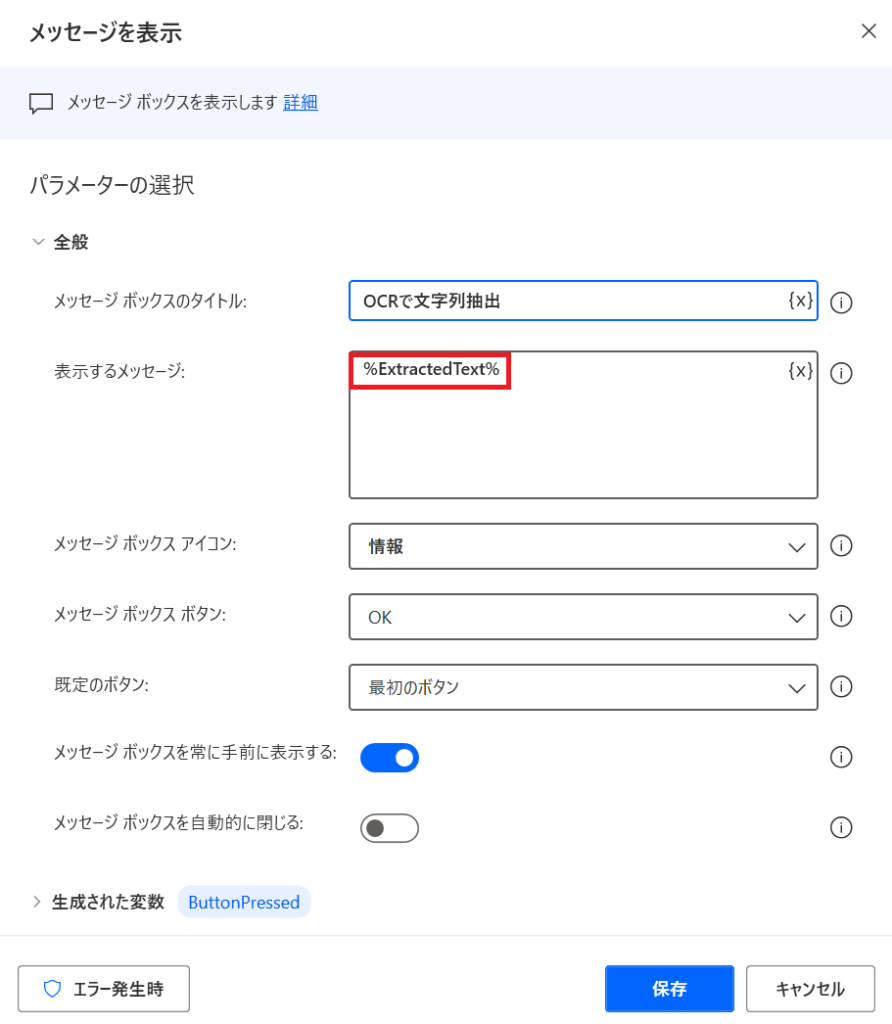
「メッセージ」アクションを追加し実行した結果は、「都道府県名」が表示されました。
3.まとめ
OCRを使用し、PDFファイルから文字列を抽出する方法を記載しました。他にもPDFファイルの内容をテキストに出力する方法などがありますが、ケースに合わせて使用してみてください。
Power Automate DeskTop PDFの該当箇所の文字を抽出





コメント