
1.はじめに
OCR機能を使用しPDFの文字列を抽出する方法を記載します。標準機能では、日本語対応をしていないため、「Tesseract」をインストールし日本語を読めるようにします。
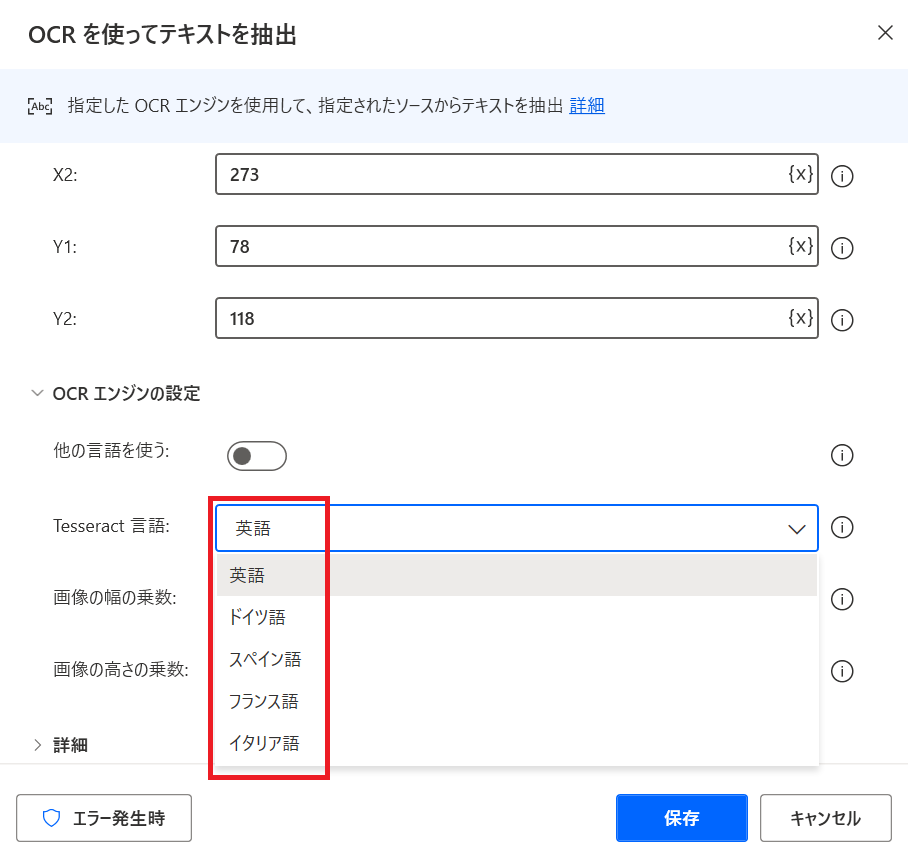
2.事前準備
2-1.Tesseractインストール
マンハイム大学図書館(UB Mannheim)も使用しているTesseractを下記より64bit版をダウンロードしインストールを行います。
Tesseract インストーラー
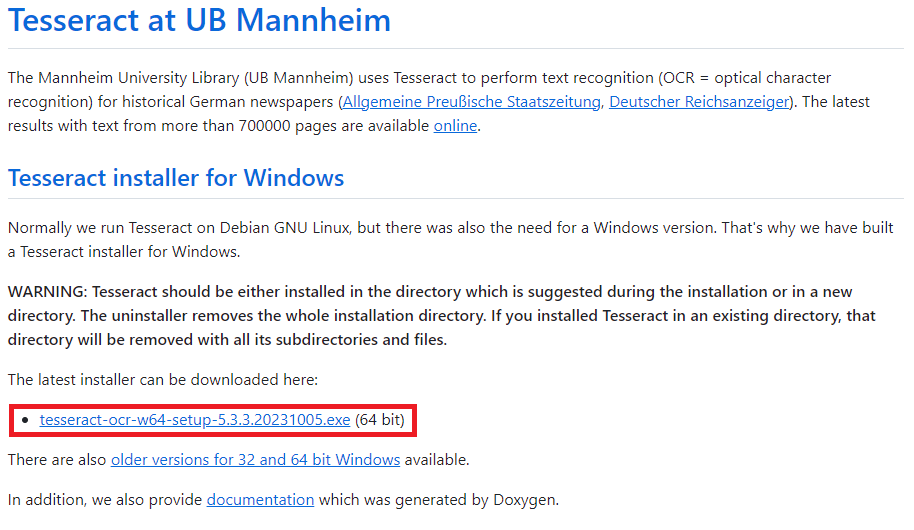
「tesseract-ocr-w64-setup-5.3.3.20231005.exe」をダブルクリックすると、ダイアログ(このアプリデバイスに変更を加えることを許可しますか?)が表示されますので、「はい」をクリックします。
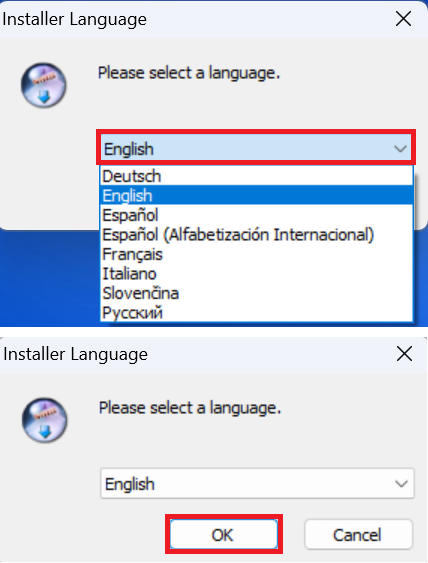
言語選択のダイアログが表示されますが、日本語がないので「English」を選択し「OK」をクリックします。
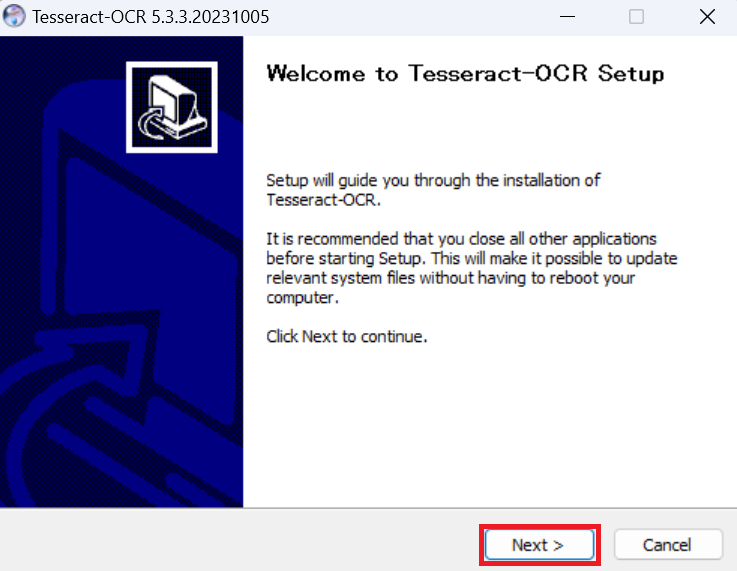
デフォルトのまま「Next」をクリックします。
「I Agree」をクリックします。
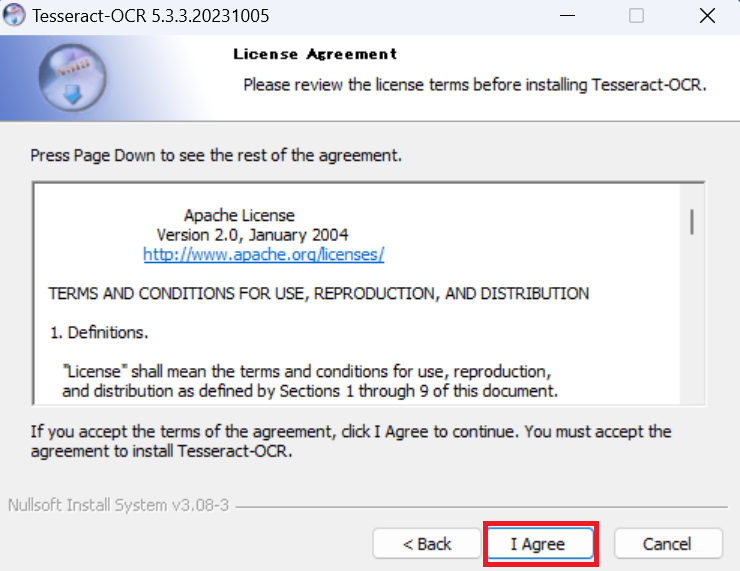
「Install for anyone this computer」を選択し、「Next」をクリックします。
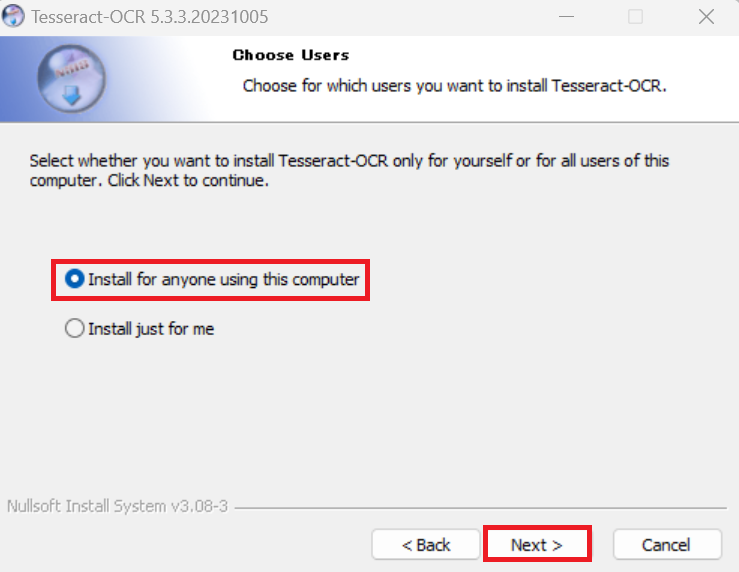
Choose Components画面で「Additional script data (download)」⊞をクリックし展開します。
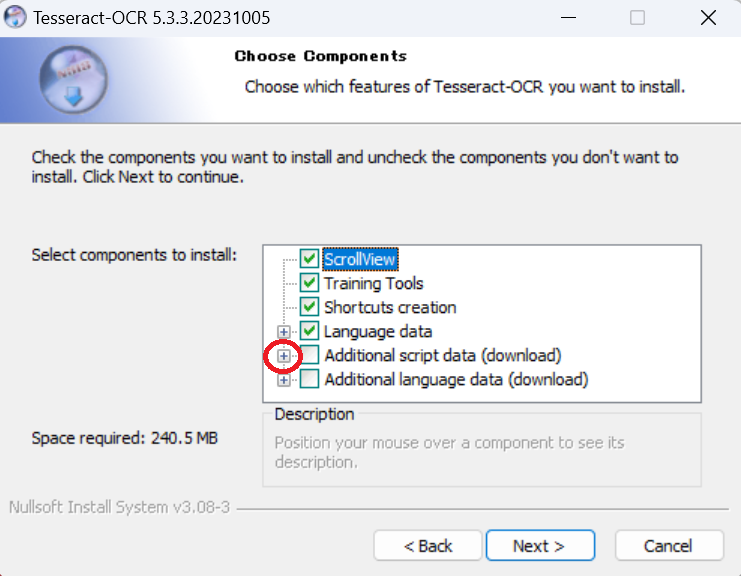
Japaneseから始まる2つを選択しします。
ここでは、「Next >」をクリックしないでください。
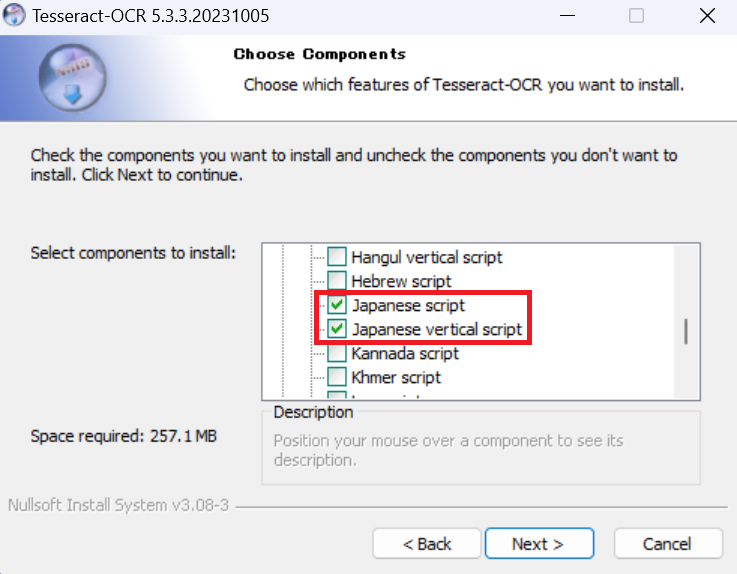
Choose Components画面で「Additional language data (download)」⊞をクリックし展開します。
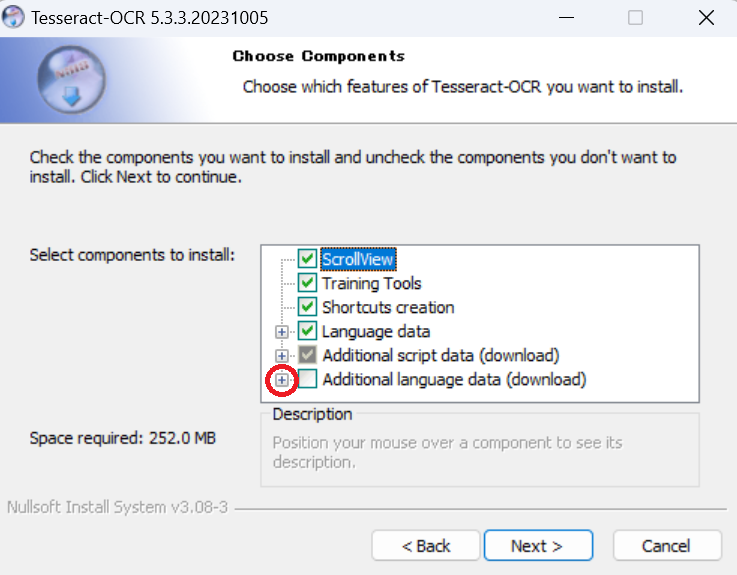
Japaneseから始まる2つを選択し、「Next >」ボタンをクリックします。
※「Javanese」は、放念ください
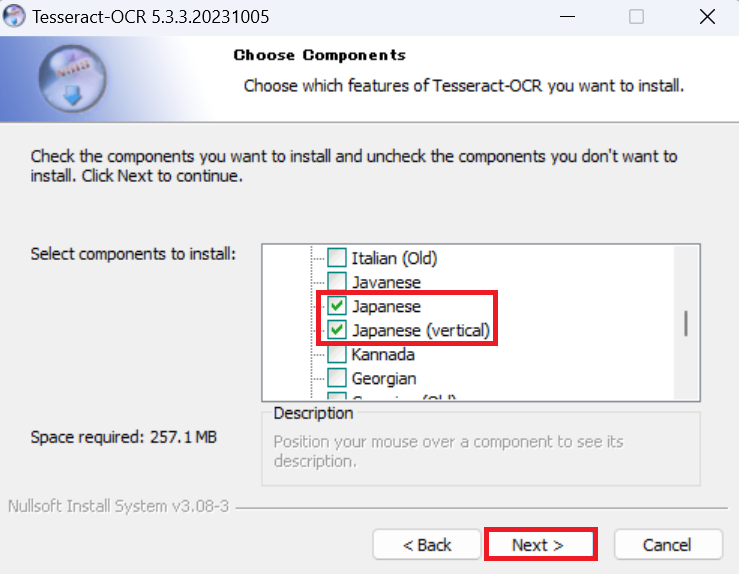
デフォルトのまま「Next >」をクリックします。
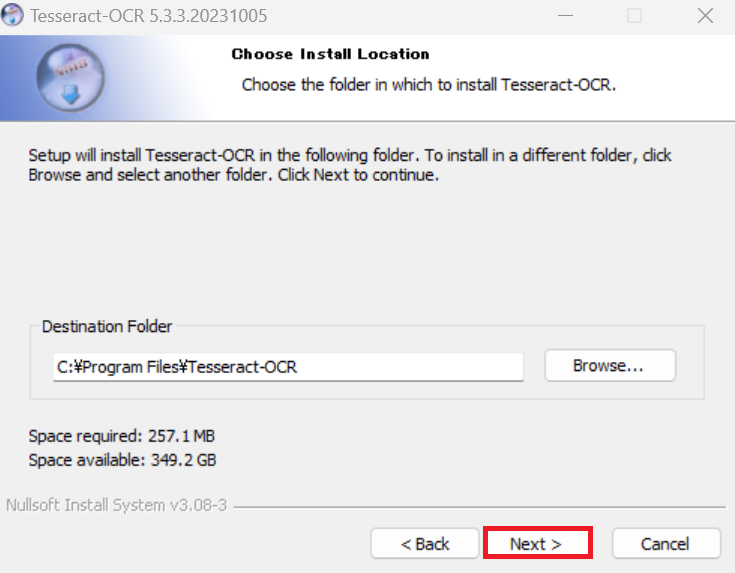
「Install」をクリックします。
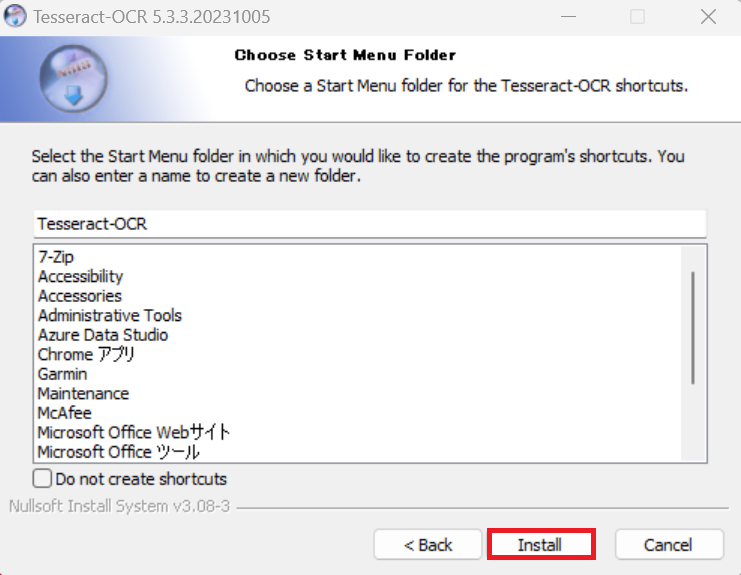
インストールが完了しましたので、「Finish」をクリックします。
2-2.動作確認
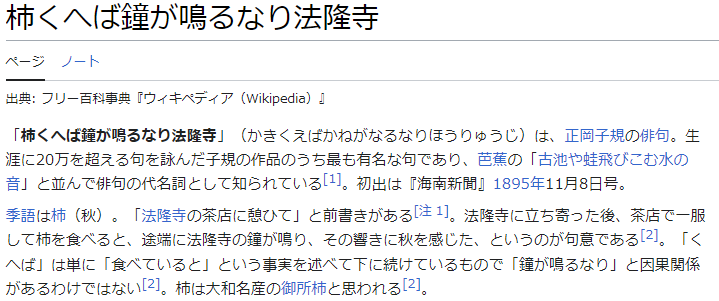
画像ファイル(test.png)から文字を認識しテキストファイルに書き出せるか検証します。
コマンドプロンプトを起動し、下記のコマンドを実行します。
詳しくは、コマンドラインの使用法を参照
C:\PDF>"C:\Program Files\Tesseract-OCR\tesseract.exe" test.png test_out -l jpn
C:\PDFフォルダにtest_out.txtファイルが作成されていますのでメモ帳で確認します。
認識誤りの文字が存在しますが、動作検証は問題なさそうです。

3.まとめ
今回は「OCRでPDFの文字列を抽出」の事前準備として、OCRで日本語を読み取れるようにTesseractのインストール方法を記載しました。次回は、Power Automate DeskTopのOCR機能を使用しPDFから文字列を抽出する方法を記載します。




コメント