
1.はじめに
PDFの該当箇所の文字をPower Automateのテキスト分割アクションを使用し抽出する方法を記載します。
2.PDFの該当箇所の文字抽出
2-1.抽出する文字の選択
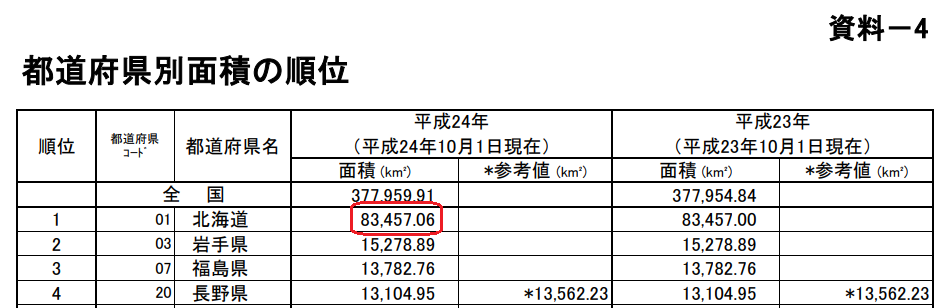
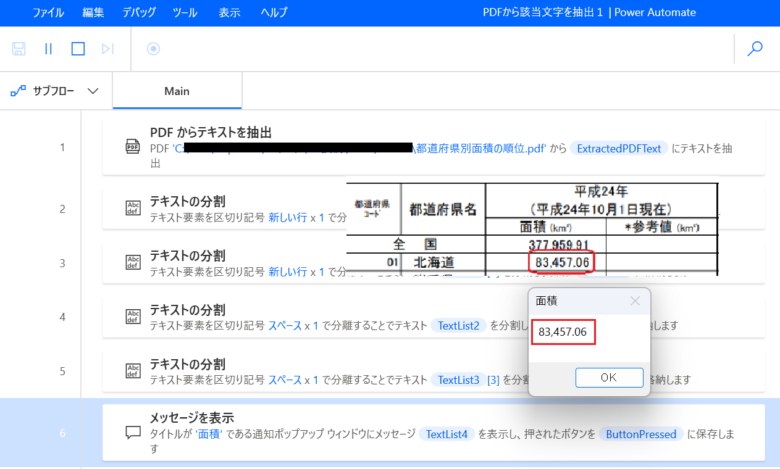
北海道の平成24年10月1日現在の面積:[83,457,06]を抽出し、メッセージに出力します。
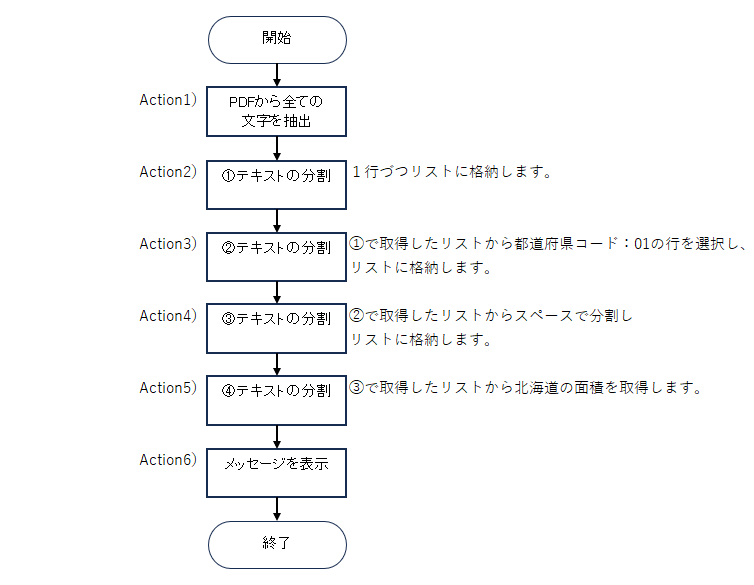
2-2.PDFから該当文字を抽出する流れ
2-2.詳細
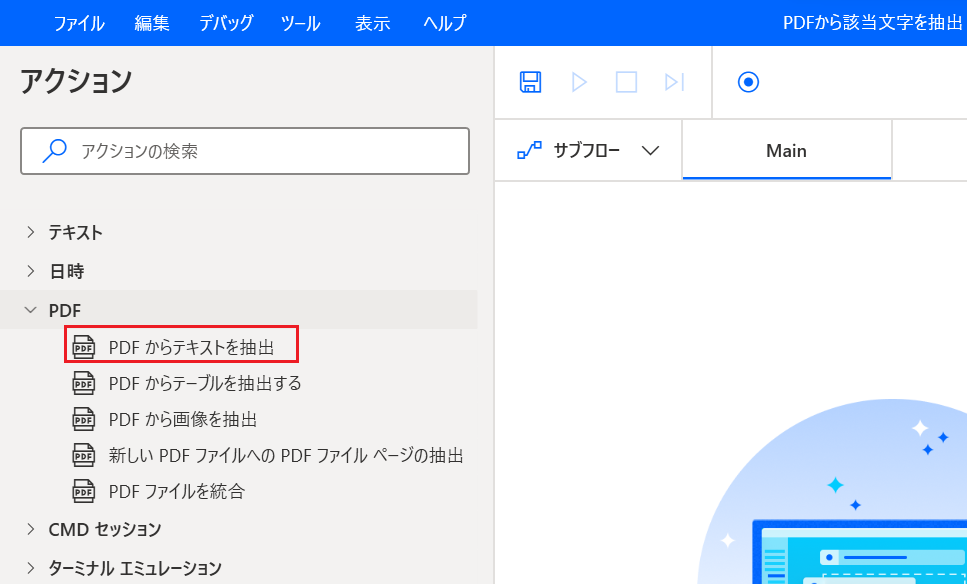
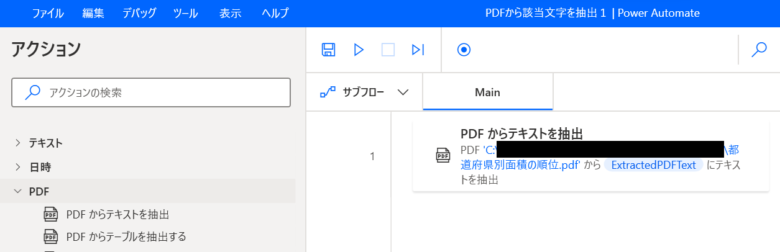
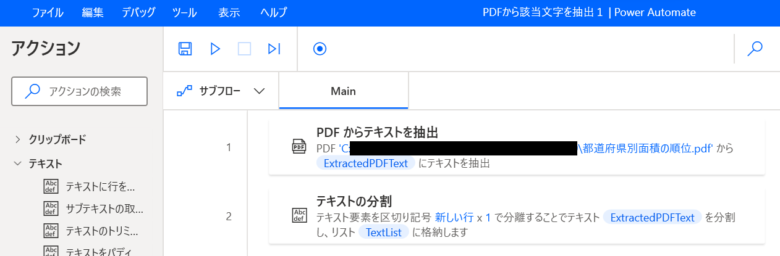
Action1 PDFから全ての文字を抽出
「PDFからテキストを抽出」をダブルクリックします。
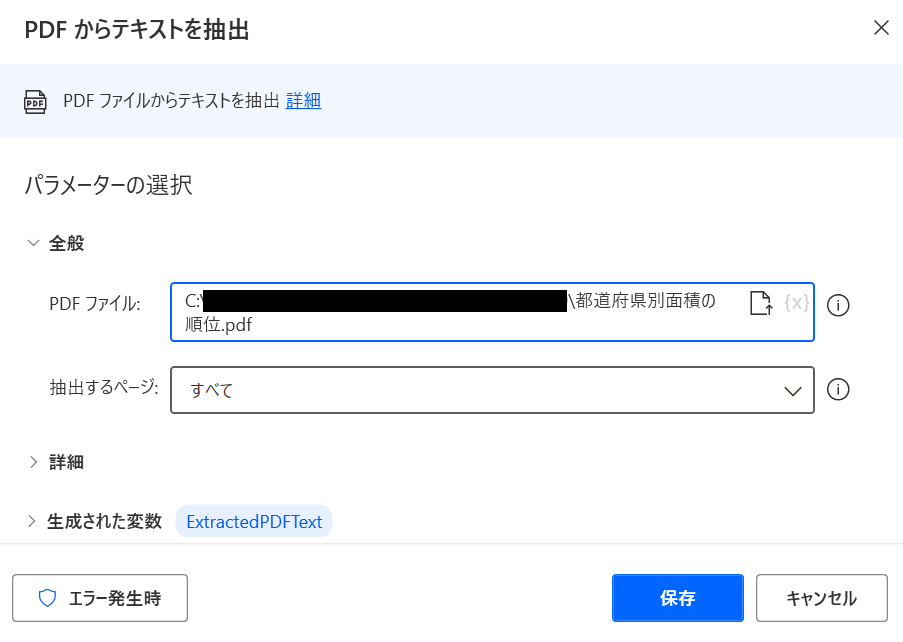
PDFファイル: 該当のPDFファイルを選択。PDFの取得URLは、「都道府県別面積の順位」か ら取得しました。
抽出するページ: 「すべて」を選択。
「保存」をクリックします。
Mainフローに「PDFからテキストを抽出」アクションが作成されました。
Action2 ①テキストの分割
「テキストの分割」をダブルクリックします。
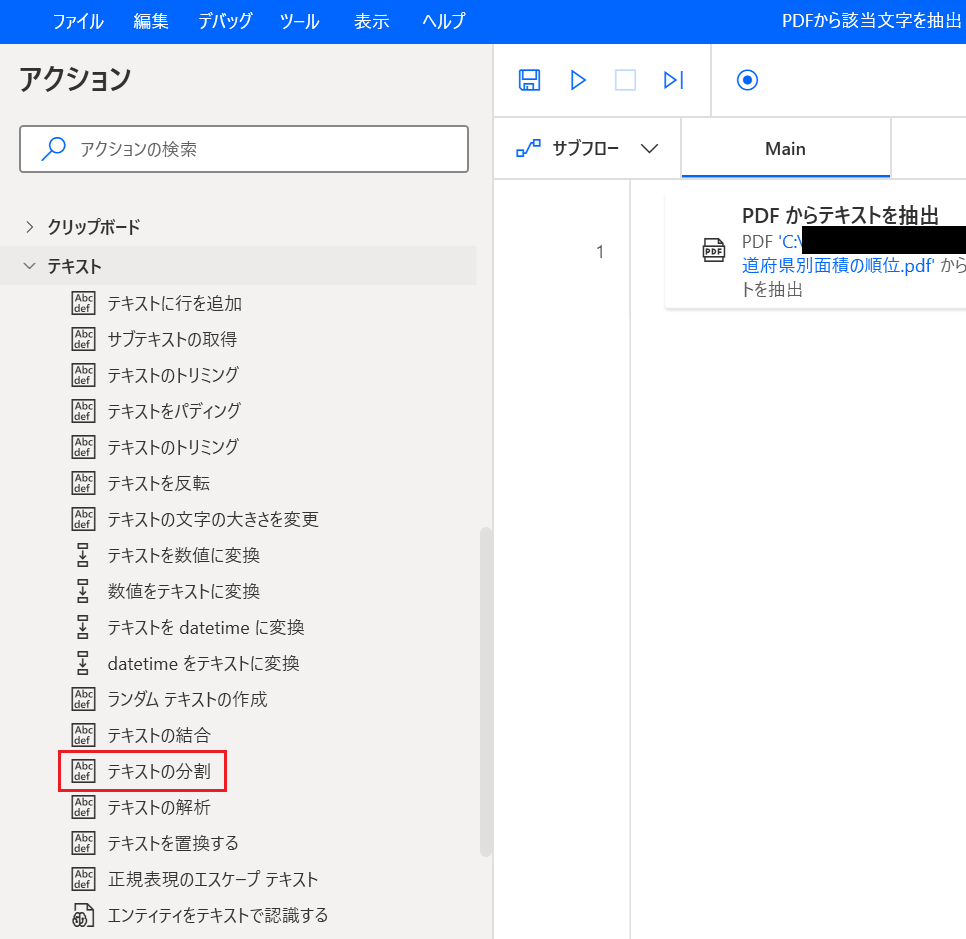
分割するテキスト: {x}をクリックし「ExtractedPDFText」を選択。
区切り記号の種類: 「標準」のままを選択。
標準の区切り記号: 「新しい行」を選択。
回数: 「1」のままを選択。
「保存」をクリックします。
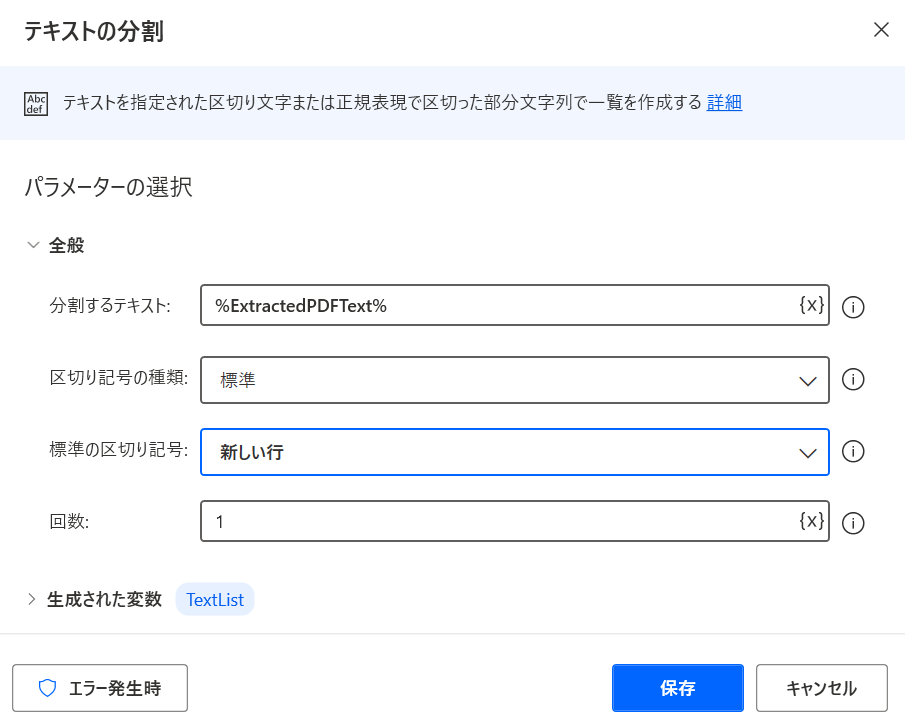
TextListに格納された値になり、Index 4に該当データが格納されています。
Mainフローに「テキストの分割」が作成されました。
Action3 ②テキストの分割
「テキストの分割」をダブルクリックします。
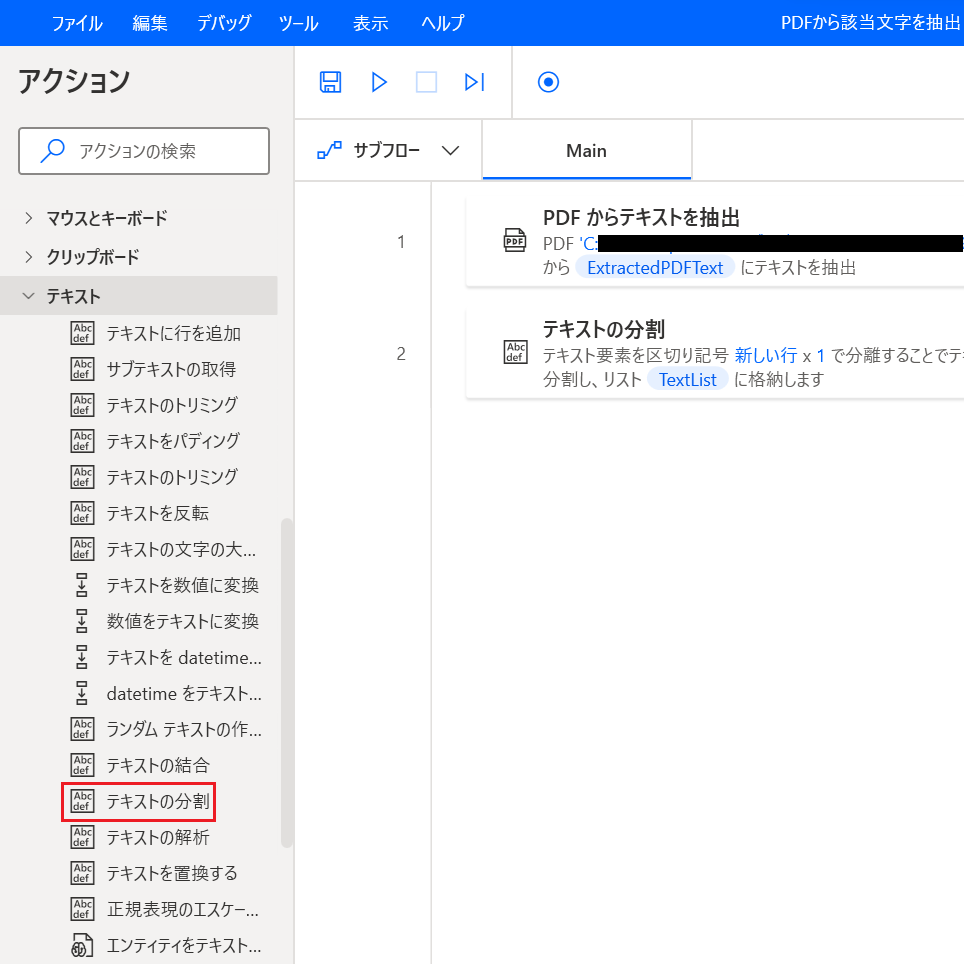
分割するテキスト: {x}をクリックし「TextList」を選択しIndex「[4]」を追記。
区切り記号の種類: 「標準」のままを選択。
標準の区切り記号: 「新しい行」を選択。
回数: 「1」のままを選択。
「保存」をクリックします。
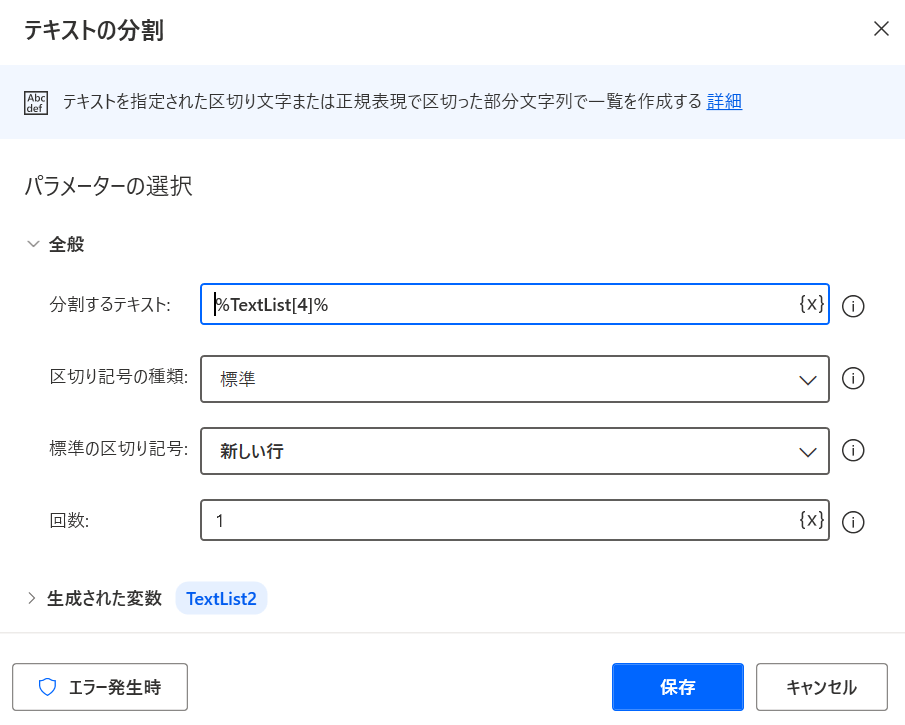
TextList2に格納された値になり、TextListから該当データを抽出し格納されています。
Mainフローに2つめの「テキストの分割」が作成されました。
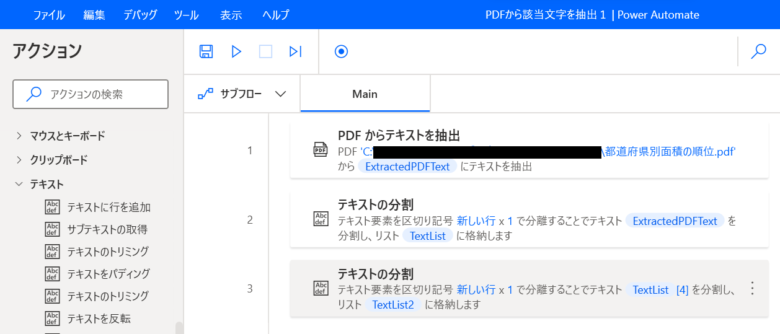
Action4 ③テキストの分割
「テキストの分割」をダブルクリックします。
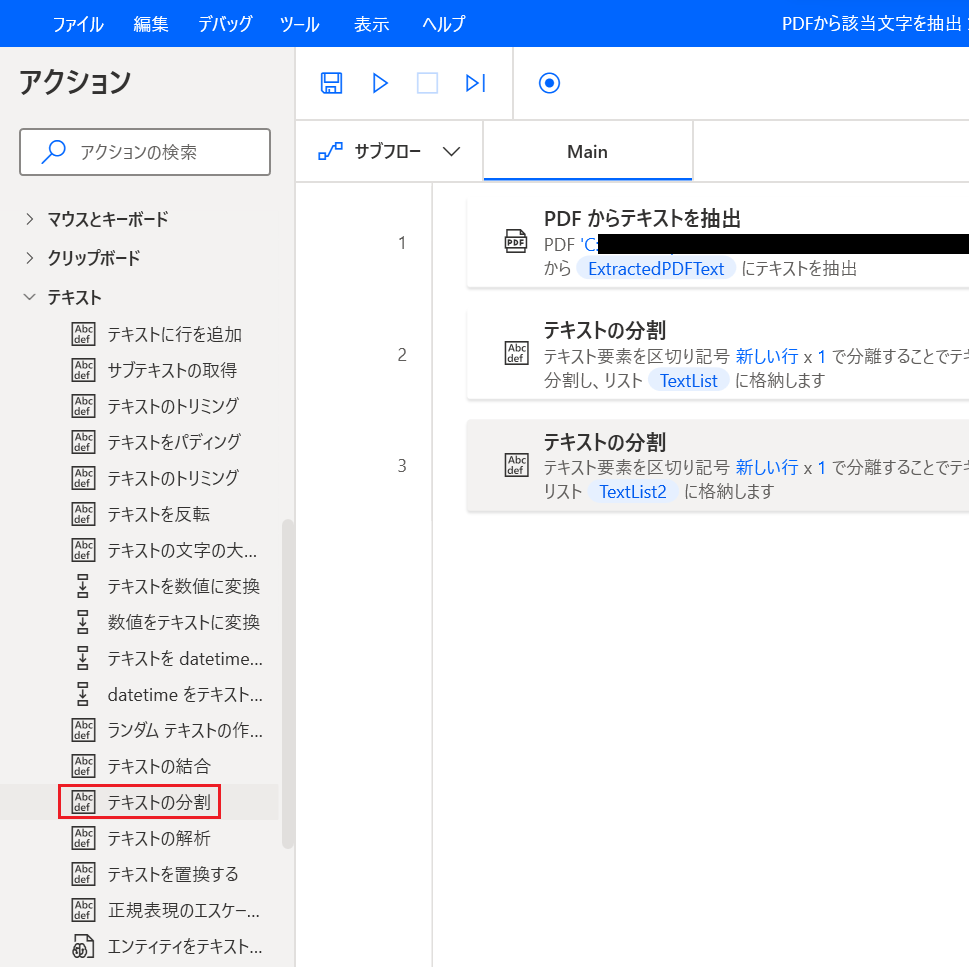
分割するテキスト: {x}をクリックし「TextList2」を選択。
区切り記号の種類: 「標準」のままを選択。
標準の区切り記号: 「スペース」のままを選択。
回数: 「1」のままを選択。
「保存」をクリックします。
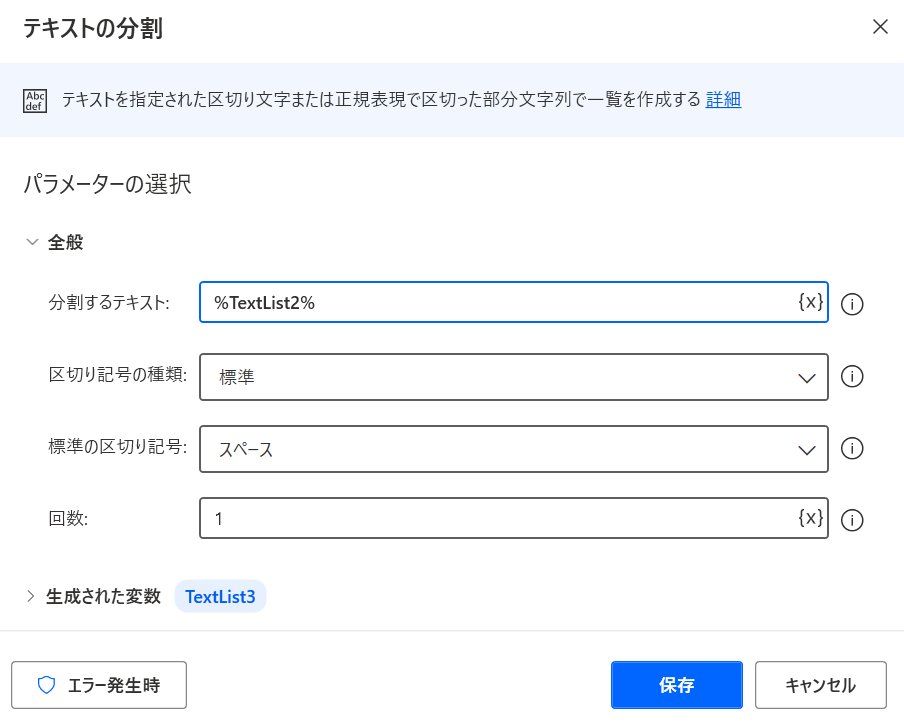
TextList3に格納された値になり、TextList2から分割し該当データがIndex 3に格納されています。
Mainフローに3つめの「テキストの分割」が作成されました。
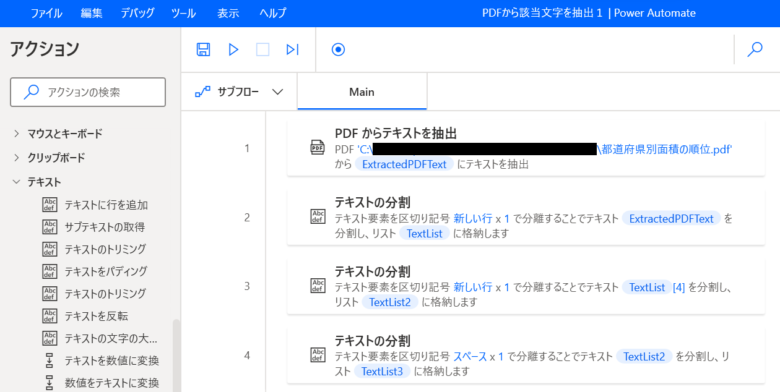
Action5 ④テキストの分割
「テキストの分割」をダブルクリックします。

分割するテキスト: {x}をクリックし「TextList3」を選択しIndex「[3]」を追記。
区切り記号の種類: 「標準」のままを選択。
標準の区切り記号: 「スペース」のままを選択。
回数: 「1」のままを選択。
「保存」をクリックします。
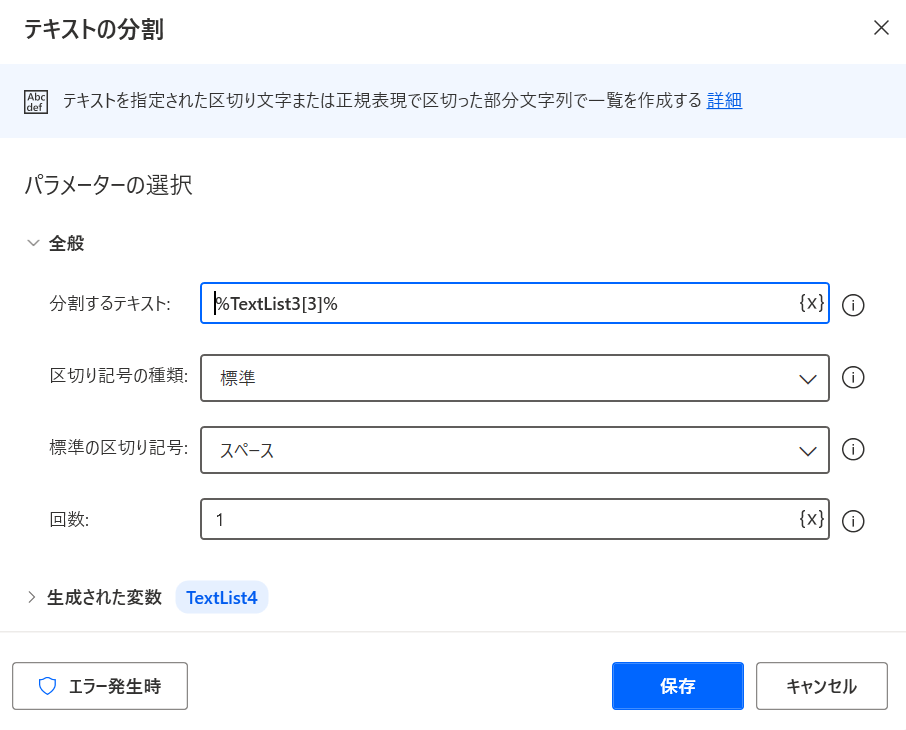
TextList4に格納された値になり、該当データが格納されています。
Mainフローに4つめの「テキストの分割」が作成されました。
Action6 メッセージを表示
「メッセージを表示」をダブルクリックします。
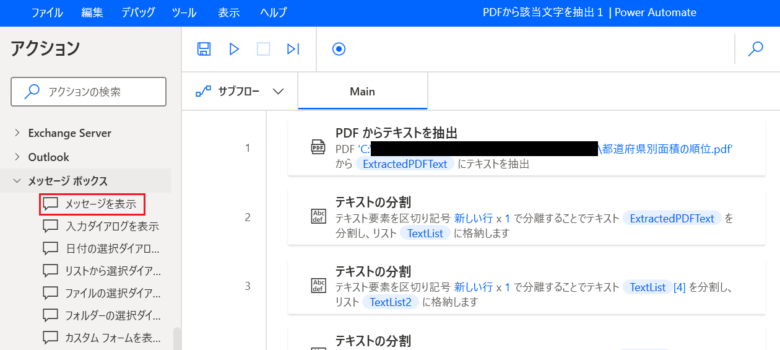
メッセージボックスのタイトル: 「面積」を入力。
表示するメッセージ: {x}をクリックし「TextList4」を選択。
メッセージボックスアイコン: 「いいえ」のままを選択。
メッセージボックスボタン: 「OK」のままを選択。
既定のボタン: 「最初のボタン」のままを選択。
「保存」をクリックします。
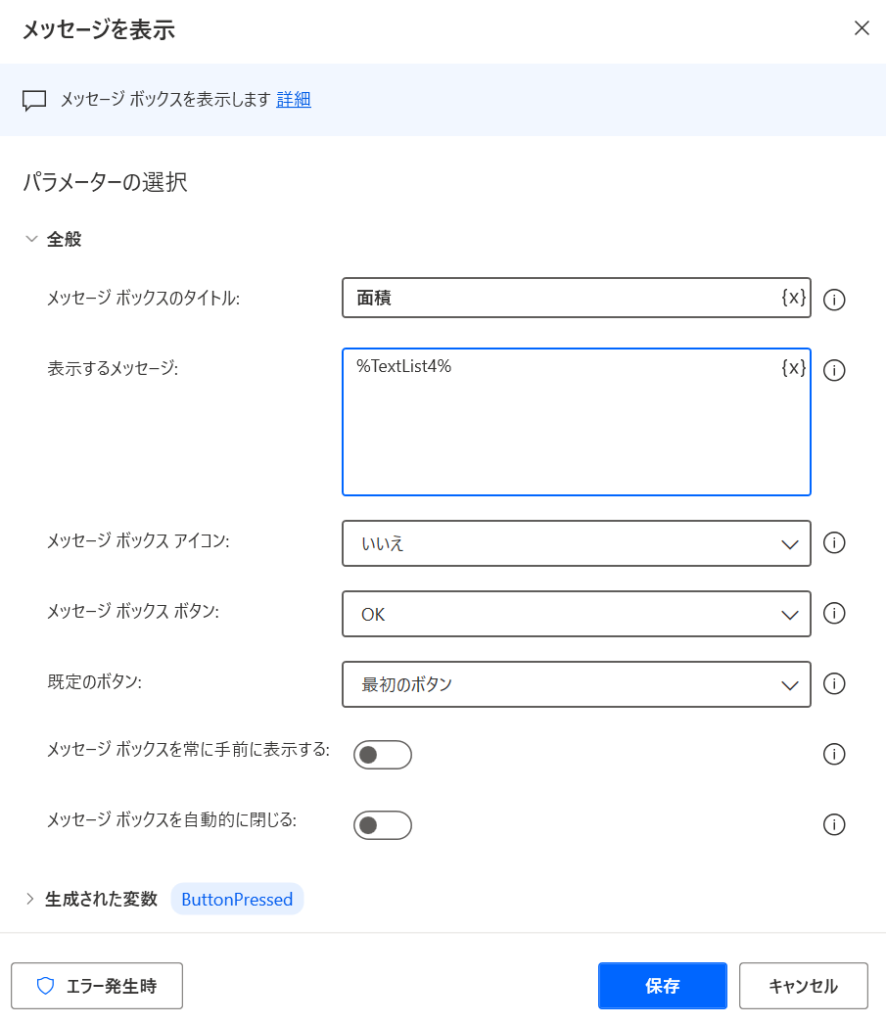
Mainフローに「メッセージを表示」が作成されました。
3.実行結果
「実行」をクリックします。
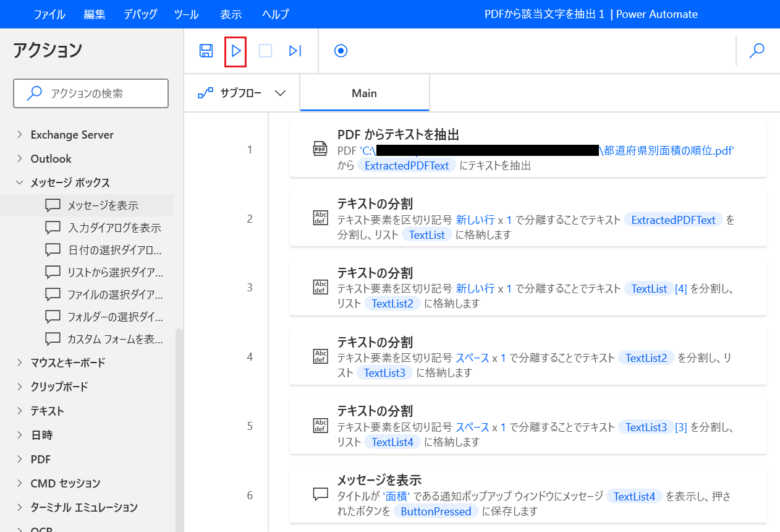
フローの実行結果とPDFの該当データと一致しています。
4.まとめ
今回は、テーブル形式のPDFファイルのため「PDFからテキストを抽出」、「テキストの分割」アクションを使用しPDFファイルから該当箇所の文字を抽出しました。PDFファイルがテーブル形式でない場合は、OCR機能の使用も検討をお願いします。





コメント